![[レポート]InfluxDBでリアルタイムインテリジェントシステムを構築する Build real-time intelligent systems with InfluxDB (sponsored by InfluxDB)](https://images.ctfassets.net/ct0aopd36mqt/3IQLlbdUkRvu7Q2LupRW2o/edff8982184ea7cc2d5efa2ddd2915f5/reinvent-2024-sessionreport-jp.jpg?w=3840&fm=webp)
[レポート]InfluxDBでリアルタイムインテリジェントシステムを構築する Build real-time intelligent systems with InfluxDB (sponsored by InfluxDB)
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
本記事は「AWS re:Invent 2024 - Build real-time intelligent systems with InfluxDB (sponsored by InfluxData) | DAT101-S」のセッションレポートです。
セッション動画は以下で公開されています。
概要
[概要]
In this lightning talk, explore the world of time series data and how InfluxDB, a purpose-built time series database, enables the creation of intelligent real-time systems. Learn about defining time series data and databases and their importance in modern applications. Then, learn about InfluxData and see how InfluxDB solves complex analytical problems with its powerful features. This presentation is brought to you by InfluxDB, an AWS Partner.
[機械翻訳]
このライトニングトークでは、時系列データの世界と、専用の時系列データベースであるInfluxDBがどのようにインテリジェントなリアルタイムシステムの作成を可能にするかを探ります。時系列データとデータベースの定義、および最新のアプリケーションにおけるその重要性について学びます。その後、InfluxDataについて学び、InfluxDBがその強力な機能によって複雑な分析問題をどのように解決するかをご覧ください。本プレゼンテーションは、AWSパートナーであるInfluxDBがお届けします。
自分なりに要約
以下は私なりの要約です。
InfluxDBが扱っている時系列データってどんなデータだろう?
実際のユースケースを参考にInfluxDBについて学んでいきましょう。
また、最新のInfluxDB 3.0がどのような機能であるかについても説明します。
最後に規模に応じたソリューションの使い分けについても紹介します。
ローカル開発、小規模、大規模と規模ごとに必要な要件は異なります、要件にあったソリューションを使っていきましょう。
こんな人に見てほしい
時系列データがなんなのか知りたい。
InfluxDBのバージョン3.0が気になる。
InfluxDBを使っているけどインフラ管理など、困っていることがある。
大規模な時系列データを扱う場合のソリューションを知りたい。
例えば、オープンソースのInfluxDBを使っているけど他にInfluxDBを利用する方法はないのか?という方には特におすすめです。
内容
InfluxDataとは
InfluxDataとはどのような会社でしょうか?
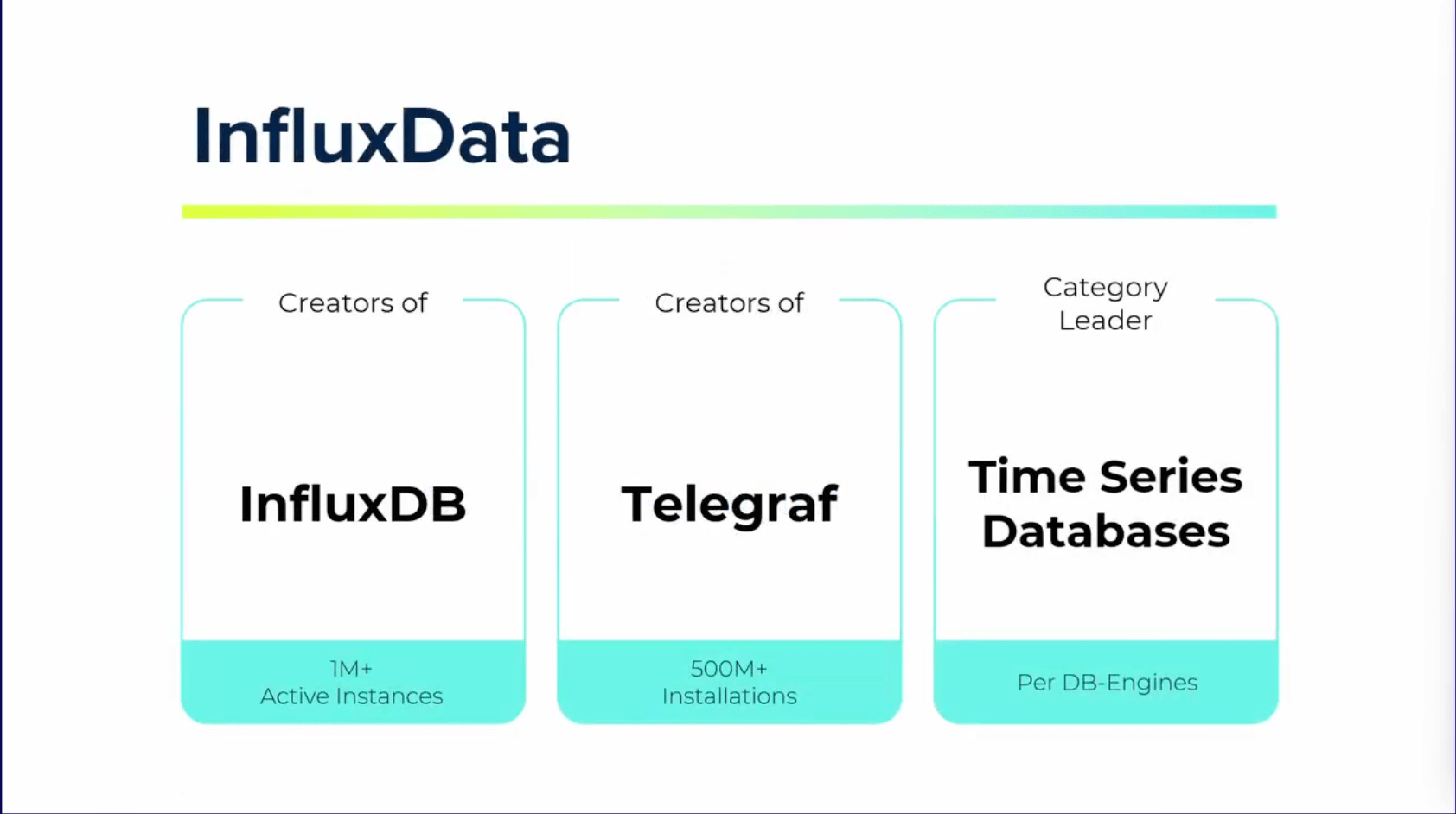
InfluxDBの開発元であり、Telegrafの開発者でもあります。
ちなみに、
InfluxDBは時系列データに特化したデータベースです。
Telegrafはデータベース、システム、IoTセンサーからメトリクスを収集するエージェントです。
InfluxDBの歴史
InfluxDBの歴史を振り返ります。

2016年に1.0をリリースしました。
このバージョンは主に、大量のデータをどのように取り込み、処理し、変換しするかということに重きを置いてました。
次に2020年に2.0をリリースしました。
このバージョンでは使いやすい処理言語を実装して、データの理解、変換、集約など深い洞察を得ることができるようになりました。
最新の3.0は2023年にリリースされました。
このバージョンはリアルタイムのカラム型データベースです。
1秒未満、100ミリ秒未満、さらに短い時間で応答が可能なため、イベントの発生時など何か問題が発生した際のクエリには最適なデータベースになっています。
時系列データとは?
そもそも時系列データとはなんでしょうか?
手首の脈拍を測ってみて下さい。
それが時系列データです。
つまり、特定の時点で何が起こっているのかを知ることを目的としたデータのことです。

よくある例だと、IoTのセンサーデータですね。それ以外にも車の走行データなど日常生活の中にも様々な時系列データが存在します。
時系列データにはメトリクスとイベントという2つのタイプがあります。
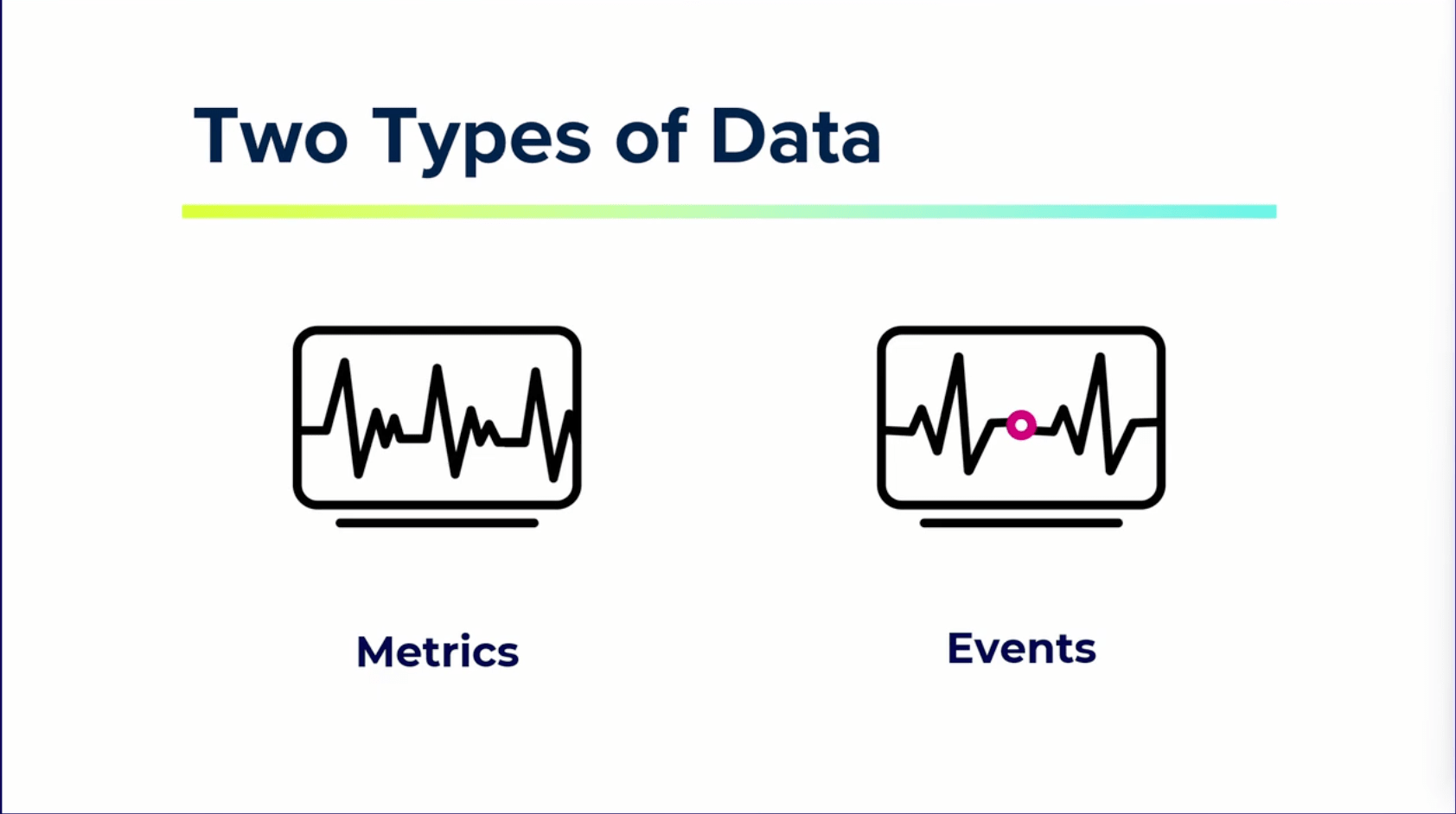
メトリクス
先ほどの例だと、一定のペースで継続的に取得できる脈拍のようなものです。
イベント
心臓に異常があると、一定ペースの脈拍から突然の変動が起こります。
つまり、標準のプロセスから外れたパターンというのがイベントです。
実際のデータで言うとサーバーのCPU使用率が急上昇するようなデータはイベントとして登録されます。
こういったイベントにミリ秒単位で対応することで、システムの正常性を保ち、予期しないダウンタイムを防ぐことができます。
InfluxDB 3.0の特徴
InfluxDB 3.0にはどのような特徴があるのでしょうか?
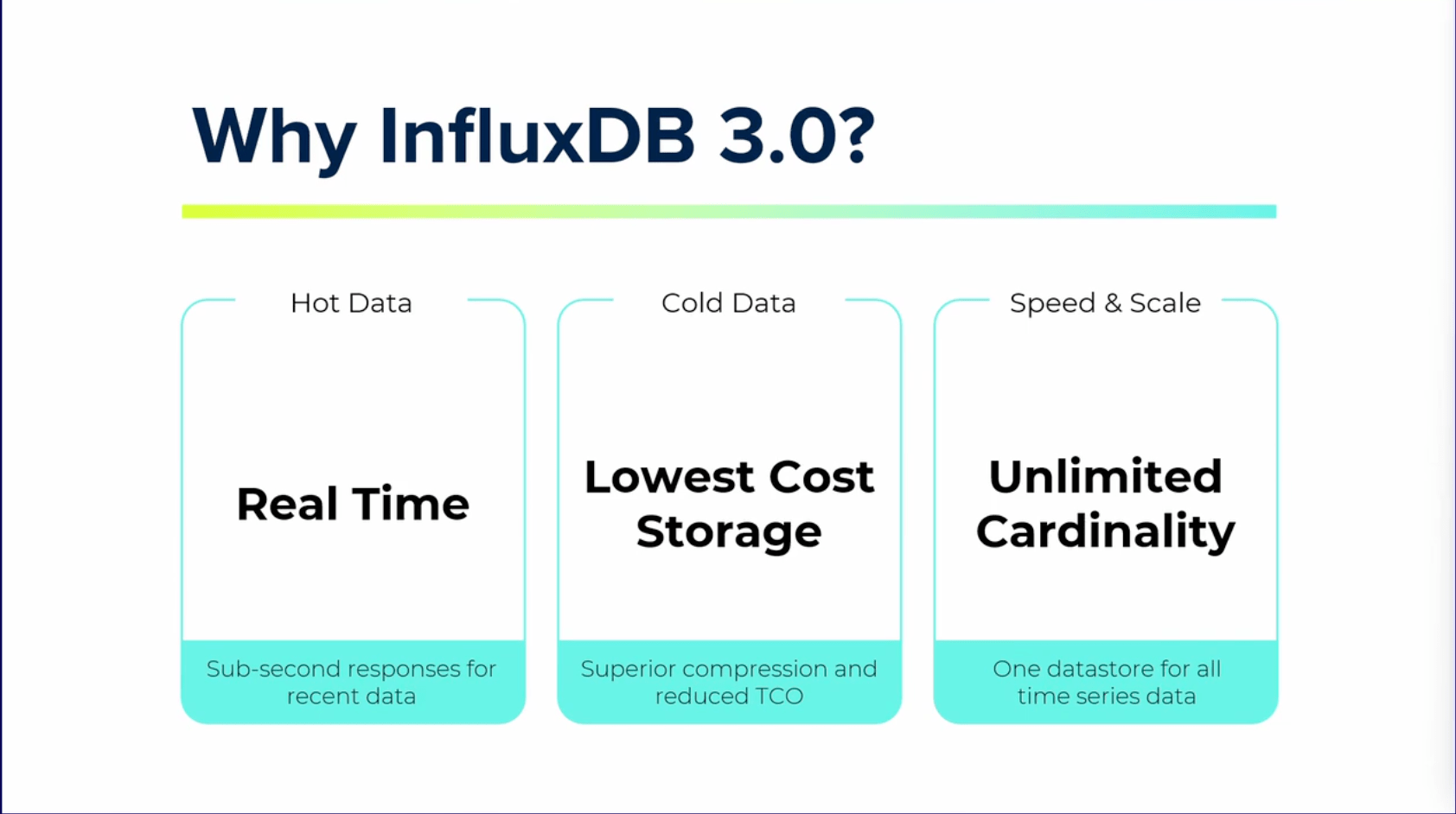
リアルタイム処理
InfluxDB 3.0はリアルタイムの処理能力が高く、100ミリ秒未満の応答が達成しています。
これにより迅速な意思決定が可能になります。
例えば、システム障害の早期検出や、金融取引における瞬間的な判断など、リアルタイムデータが重要とされるシナリオではInfluxDBのリアルタイム処理能力が重要になります。
ストレージコスト
やはりストレージのコストも重要です。
データフォーマットには分析ワークロードに適した列志向のApache Parquetが採用されています。
これによりデータの圧縮率が向上し、ストレージコストが大幅に削減されています。
また、Apache Parquetを採用したことで、クエリ効率も向上し、大規模なデータセットでも効率的に分析が可能になったようです。
カーディナリティ
カーディナリティは属性の豊富さを表します。
従来のデータベースでは、高カーディナリティのデータを扱う際にパフォーマンスが低下するという問題がありましたが、バージョン3.0ではこの問題は解決しました。
これにより、例えば数百万のIoTデバイスからのデータ受け取るような、大規模で複雑なデータセットも効率的に処理できるようになりました。
リアルタイム分析
リアルタイム分析にはOLAPとOLTPというデータ処理システムがあります。
OLAP(Online Analytical Processing): 大量のデータを分析して処理するのに向いている
OLTP(Online Transaction Processing): リアルタイムトランザクション処理の管理と処理に向いている
特にOLAPは列指向のデータ処理が可能で、これがリアルタイム分析適しているそうです。
例えば、サーバーのCPU使用率データのみを高速に分析することで、リアルタイムにサーバーの障害や異常を発見して次の行動に移ることができます。

個人的にはOLAPとOLTPの違いについてはこちらが分かりやすかったです。
アーキテクチャ
古いアーキテクチャでは、データの取り込み、保存、クエリのそれぞれに遅延がありました。
新しいアーキテクチャではデータがストレージに完全に保存される前でもクエリが可能になりました。
これにより、データ処理の遅延が最小限に抑えられ、ミリ秒単位でのリアルタイム分析が可能なりました。
InfluxDBを効果的に活用する方法
利用するケースに合わせたおすすめのInfluxDBの紹介です。
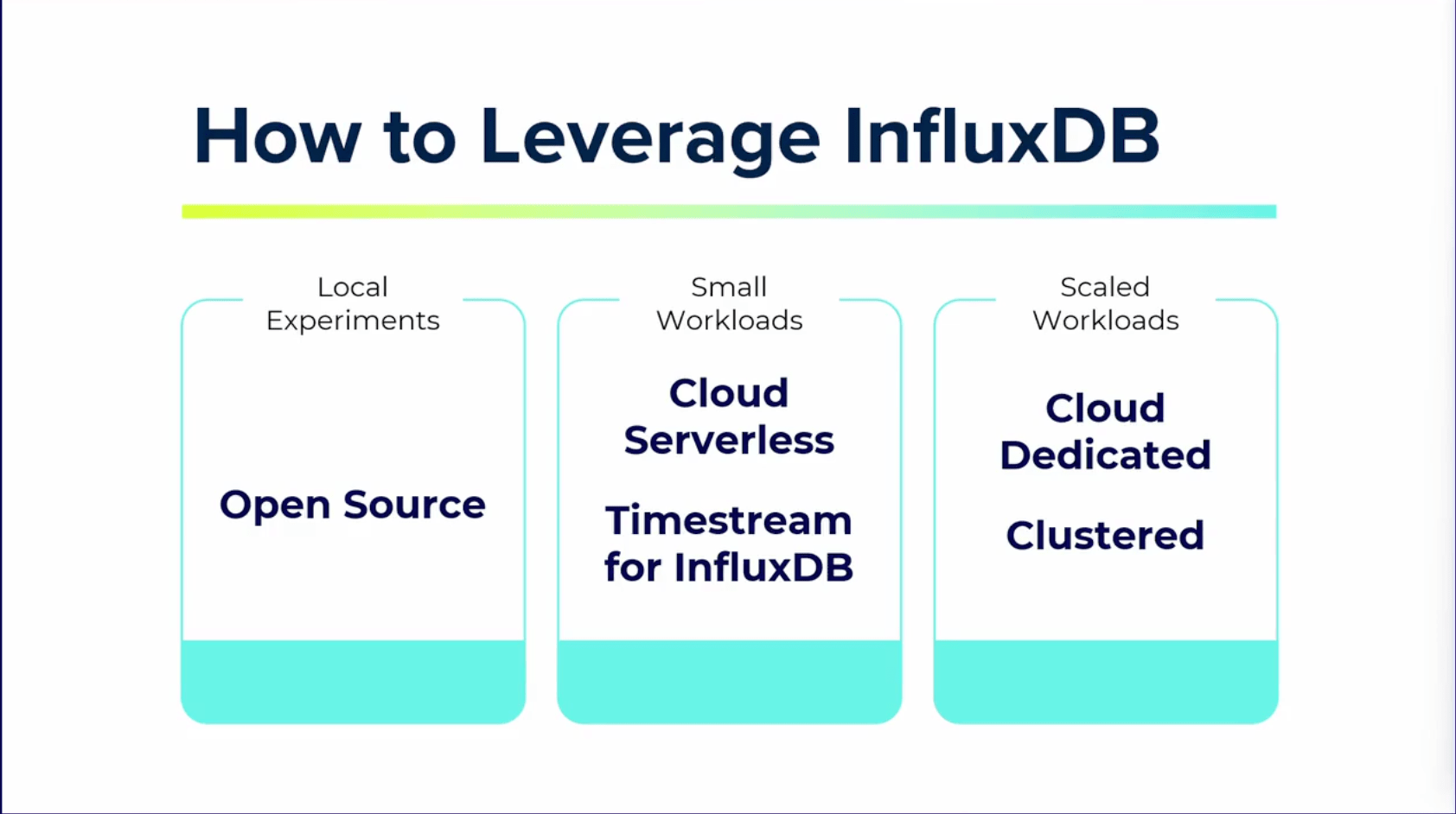
ローカル環境利用
ローカル環境ではオープンソースのInfluxDBを利用するのがおすすめです。
InfluxDataはオープンソース企業として全て製品でソースを公開しています。
オープンソースにすることによりコミュニティへの貢献や継続的な改善、透明性によるユーザーの信頼性確保などのメリットがたくさんあります。

現在OSSのInfluxDBはバージョン2.0で、第一四半期にOSS版の3.0がリリースされるそうです。
これは楽しみですね。
小規模利用
小規模の利用ではクラウドサービスを利用するのがおすすめです。
クラウドのInfluxDBを利用することで、構築の手間を省けたり、スケーリングに関して考慮することが少なくなります。
クラウドサービスの1つはInfluxDB Cloudです。
こちらは無料で始められるので、インフラ部分の構築に障壁を感じている方には特におすすめです。
また、InfluxDB内のデータを可視化するダッシュボード機能もあるため、取得したデータをすぐに可視化することができます。

他にもAWSが提供するAmazon Timestream for InfluxDBもあります。

こちらも数分で始められる素晴らしいクラウドサービスです。
ちなみに弊社でも色々とやってみたブログが上がっているのでぜひ参考にしてみて下さい。
個人的にはこちらのAmazon Timestream for InfluxDBのこれからの進化にとても期待しています。
特に他のAWSサービスとの連携については今後の展開に期待したいところです。
大規模利用
何千ものセンサーから常にデータをストリーミングしているような大規模なシステムでは、従来のデータベースモデルでは負荷に耐えられません。
対策としてInfluxDB Cloud DedicatedとClusterを使用することで大規模なシステムに耐えることができます。

InfluxDB Cloud Dedicatedはクラウドを利用してインフラストラクチャの管理を不要にしつつ、ニーズに合わせてスケーリングして可能な限り最高のパフォーマンスが出るようになっています。
Clusterは自社のプライベートクラウドや、オンプレミスのインフラストラクチャに構築したい場合にも適しています。

ClusterはKubernetes上に構築するので、AWSのEKS上にも構築できそうですね。
スケールが必要なユースケース
大規模になり得るようなユースケースを紹介します。
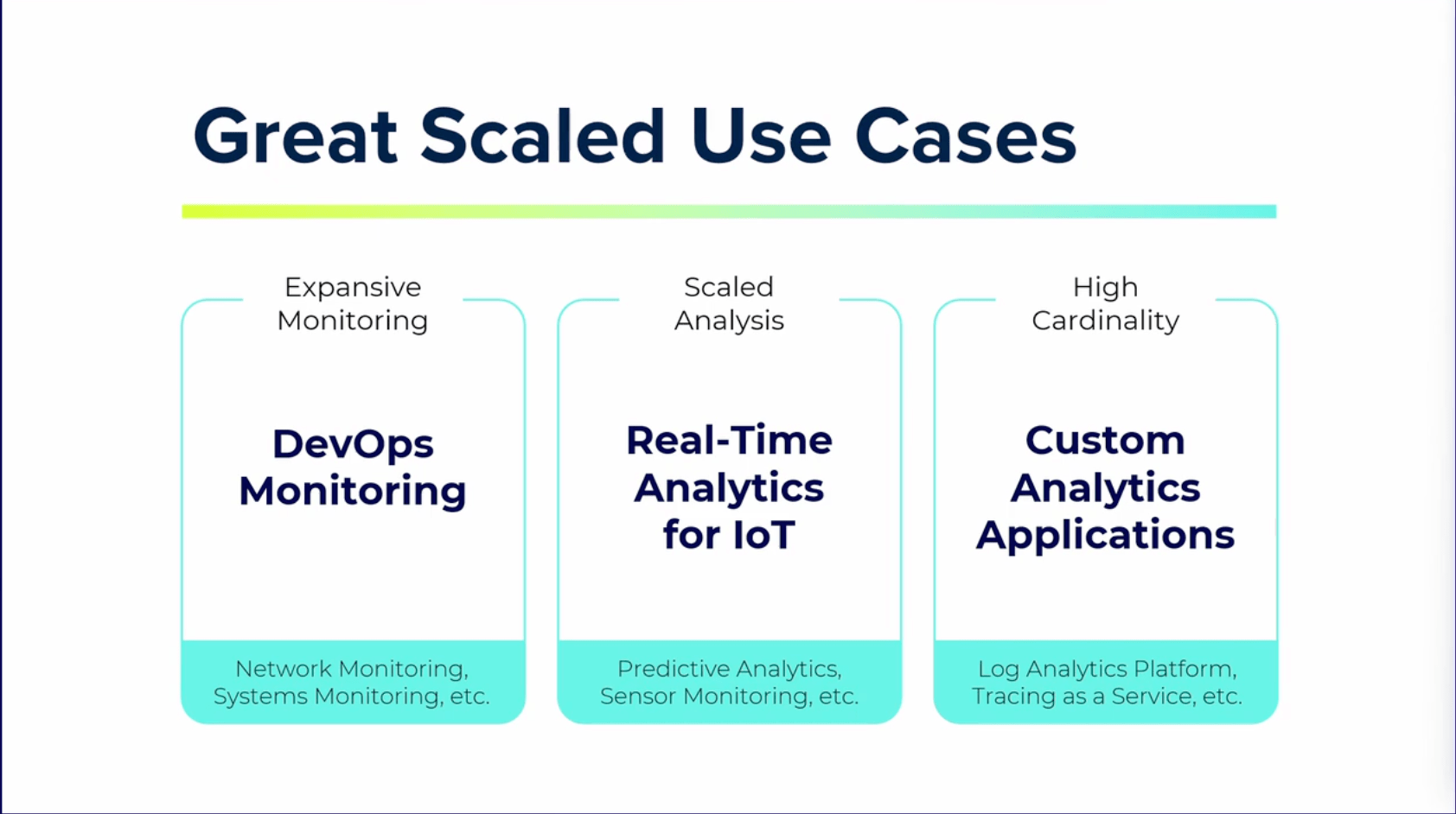
DevOps監視
広範囲の監視が必要なケースでは、ネットワークの監視やシステムの監視のために様々なパイプライン全体で何が起きているかを知る必要があります。
IoTデータのリアルタイム分析
IoTデータの分析では予測分析を中心に様々なユースケースが見られます。
こういった色々な種類の情報を全て活用しながらリアルタイムに分析する場合は大規模になるケースが多いです。
カスタム分析アプリケーション
高カーディナリティのデータを扱う分析アプリケーションについても大規模になるケースが多いです。
他のデータベースシステムで高カーディナリティのデータにクエリしようとすると、遅延が数十秒から数十分に及ぶ可能性があります。
そのため、高速なクエリ結果を維持するためにもInfluxDBを利用することが望ましいです。
最後に
今後の動きとして大規模向けのソリューションやクラウドを活用した動きが活発になりそうなので、引き続きInfluxDBの動きは注目したいと思います。









